
- 1. 情報エントロピーを用いた森林から得られる主観的情報の定量化
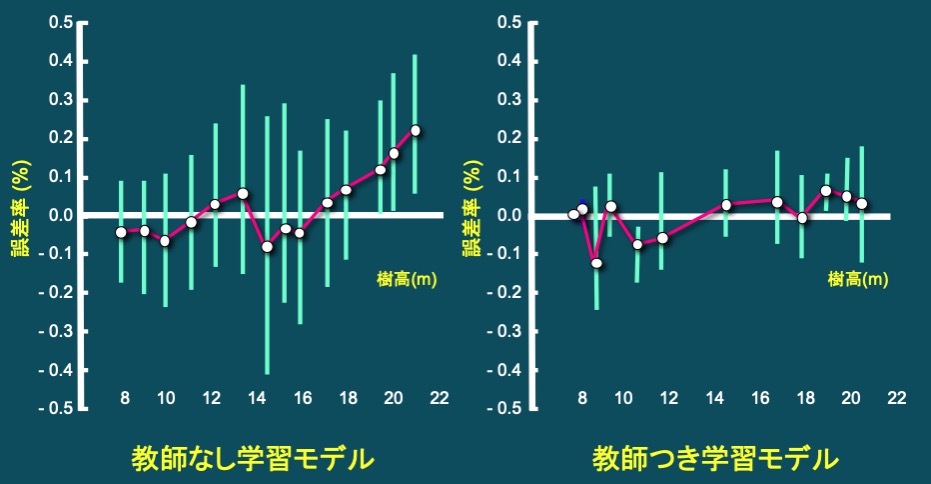
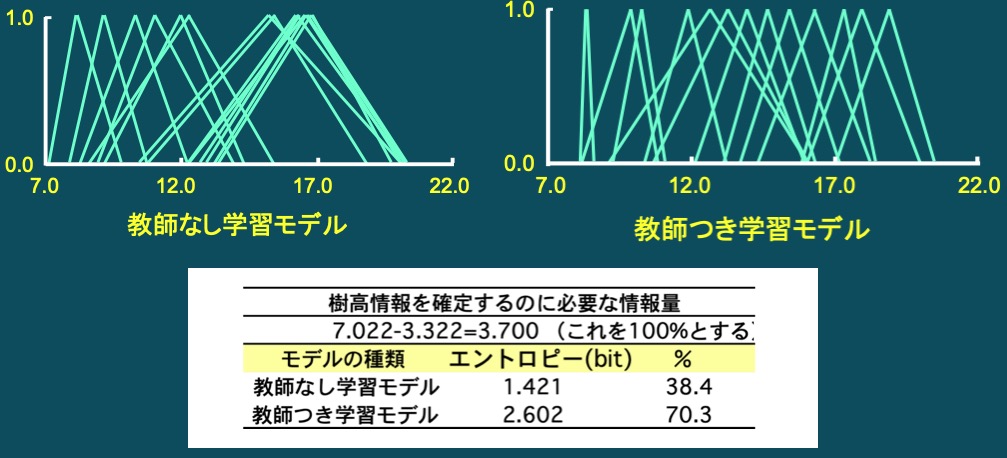
- 森林から得られる主観的情報(Subjective Forest Information)とは,人間の主観が大きく関与するもの(例えば,目測による樹高測定,樹形級区分,立木の評価等)や,それらを用いた行動(例えば,枝打ち技術,伐採木等の選木技術,経営計画おける意思決定)など「経験(則)」とか「勘」が重要な役割を示す情報のことである」と定義する(美濃羽,1995)。主観的な情報の価値がどれほどであるかを考察するため,ファジィ理論,情報エントロピー,ベイズ確率を用いて情報量を算出し定量的に評価する。その結果,教師付き学習を行うことにより適切なファジィメンバーシップ関数が構築できること,また,目測による樹高測定であっても,適切なメンバーシップ関数を用いることにより,計測器を使った測定と比べても情報抽出能力は低下しないことが明らかとなった。
- 2. 機械学習を用いた森林情報解析:間伐木選定モデルの構築
- 林業技術の中でも経験則や勘といった主観的要素が大きいと思われる間伐木の選定を取り上げ,機械学習を用いた間伐木選定モデルの構築を行った。2林分の間伐木選定データから,入力情報を量的データ(直径・樹高)および質的データ(幹形質・樹冠量・欠点)とし,出力情報を選木結果とした。
- 1. ニューラルネットワークモデル:入力・中間・出力層のニューロン数や各種パラメータを変えて学習を行い,その分類精度を比較検討するとともに,未知事例に対する分類精度も同時に検証した。その結果,出力が「間伐する・間伐しない」といった2値判断であれば,90%以上の正答率で判別することができ,また未知事例に対してもほとんど判別能力が低下しないことが明らかとなった。
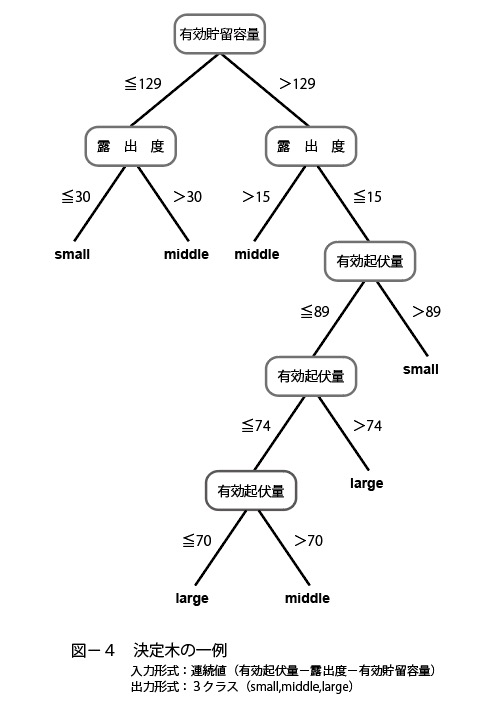
- 2. 決定木モデル:ニューラルネットワークモデルでは,入-出力関係がブラックボックス化されるため人間にとって理解しやすいモデルとは言い難い。そこで,分類結果が言語情報で表現され,知識獲得の点からも有効と考えられる決定木を用いて間伐木選定モデルを構築し,ニューラルネットワークモデルと比較した。ここでは,代表的な決定木モデルであるC4.5を用いて間伐木選定データから間伐に関わる分類規則をif-then型プロダクションルールの形として抽出し,間伐木選定モデルを構築した。そこ結果,503事例の訓練事例に対し,十分な分類精度を示すことができる分類規則は10から20程度となり,少ない規則で分類することが可能であることが明らかとなった。
- 3. 集団学習アルゴリズムを用いたモデルの汎化性の検証:これまで構築したモデルは,訓練事例に対する分類精度は十分であることが明らかとなったが,未知事例に対する分類精度に関しての検証が十分でない。そこで,5つの分類型モデルおよび1つの関数型モデルに対し,2種類の集団学習アルゴリズムとm重交差検証法を併用して,構築したモデルの訓練事例および未知事例に対する分類精度を検証した。その結果,集団学習アルゴリズムを併用することにより,分類精度を向上させることができ,また,未知事例に対しても,70%程度の分類精度を持ったモデルを構築できることを明らかにした。
- 3. 機械学習を用いた森林情報解析:地位指数選定モデルの構築
- 林地生産力を示す指標の1つである地位指数について,機械学習を用いた地位指数推定モデルの構築を行った。ここでは,GISから得られた4つの地形因子データを入力情報とし,現地における実測樹高を出力情報として地位指数の推定を行った。
- 1. ニューラルネットワークモデル:従来から用いられている重回帰分析を用いたモデルと比較検討した。モデル選択には,主成分分析法を用いてAIC,重相関係数の2変量から総合的な指標を求めた。その結果,選択された重回帰モデルの相関係数が0.5700であったのに対し,ニューラルネットワークモデルでは0.8612と高い精度で推定することができ,実用的な地位指数推定図を作成できることが明らかとなった。
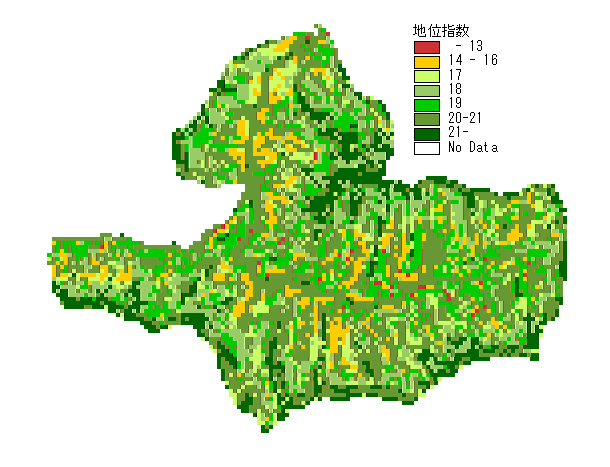
- 2. 決定木を用いた分類型モデル:ニューラルネットワークモデルに比べると推定精度は若干落ちるが重回帰モデルに比べるとかなり良い結果を示した。また,プロダクションルール数は7以下となり,少ないルールでモデルを構築することができた。
- 3. 集団学習アルゴリズムを用いたモデルの汎化性の検証: 1. これまで構築したモデルの未知事例に対する推定精度を検証するため,分類型モデル,関数型モデルともに5種類のアルゴリズムを適用し,2種類の集団学習アルゴリズムとm重交差検証法を併用したモデルを構築した。その結果,モデルによる推定精度のばらつきが大きいこと,集団学習を行うことにより推定精度が向上することがわかった。また,モデル構築するためには,様々な分類アルゴリズムを適用し,集団学習による精度向上,交差検証による未知事例に対する推定精度の検証を行い,モデルの精度を高めることが重要であることを明らかにした。
- 4. 機械学習を用いた森林情報解析:風倒木被害地分類モデルの構築
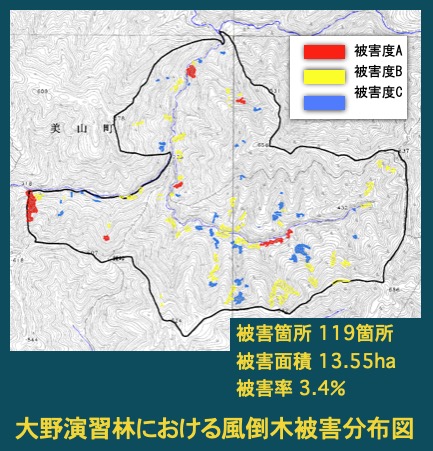
- 台風による風倒木被害は,林分構造などの林分要因や,風速や地形などの地形要因が複雑に関係し発生すると考えられる。ここでは,入力情報としてGISから算出された7つの地形因子を,出力情報として風倒被害木の有無(有の場合は被害の程度により3段階に分類)をもとに,風倒木被害発生地の分類予測および危険地域を予測するモデル構築を行った。分類予測には18の機械学習アルゴリズムを適用した。また,被害地データに比べ,被被害地を含む地形データが膨大となることから,farthest-first traversalアルゴリズムによるクラスタリングによってデータ削減を行った。その結果,未知事例に対する汎化能力より,訓練事例数を1/10に圧縮したデータからでも,全体を十分に予測することが可能であることから,データ削減が有効であることがわかった。また,分類アルゴリズムによって分類精度が大きく異なることから,様々な分類アルゴリズムを組み合わせてモデルを構築する必要が明らかとなった
- 5. 携帯端末を用いた樹種自動識別システムの開発
- 近年,IT技術の発展とともにスマートフォン等の携帯端末が普及し,様々な分野に応用した研究あるいはアプリケーションの開発が行われている。そこで,携帯端末を用いた樹木検索システムの構築を主目的とした樹種判別アルゴリズムについての検討を行った。
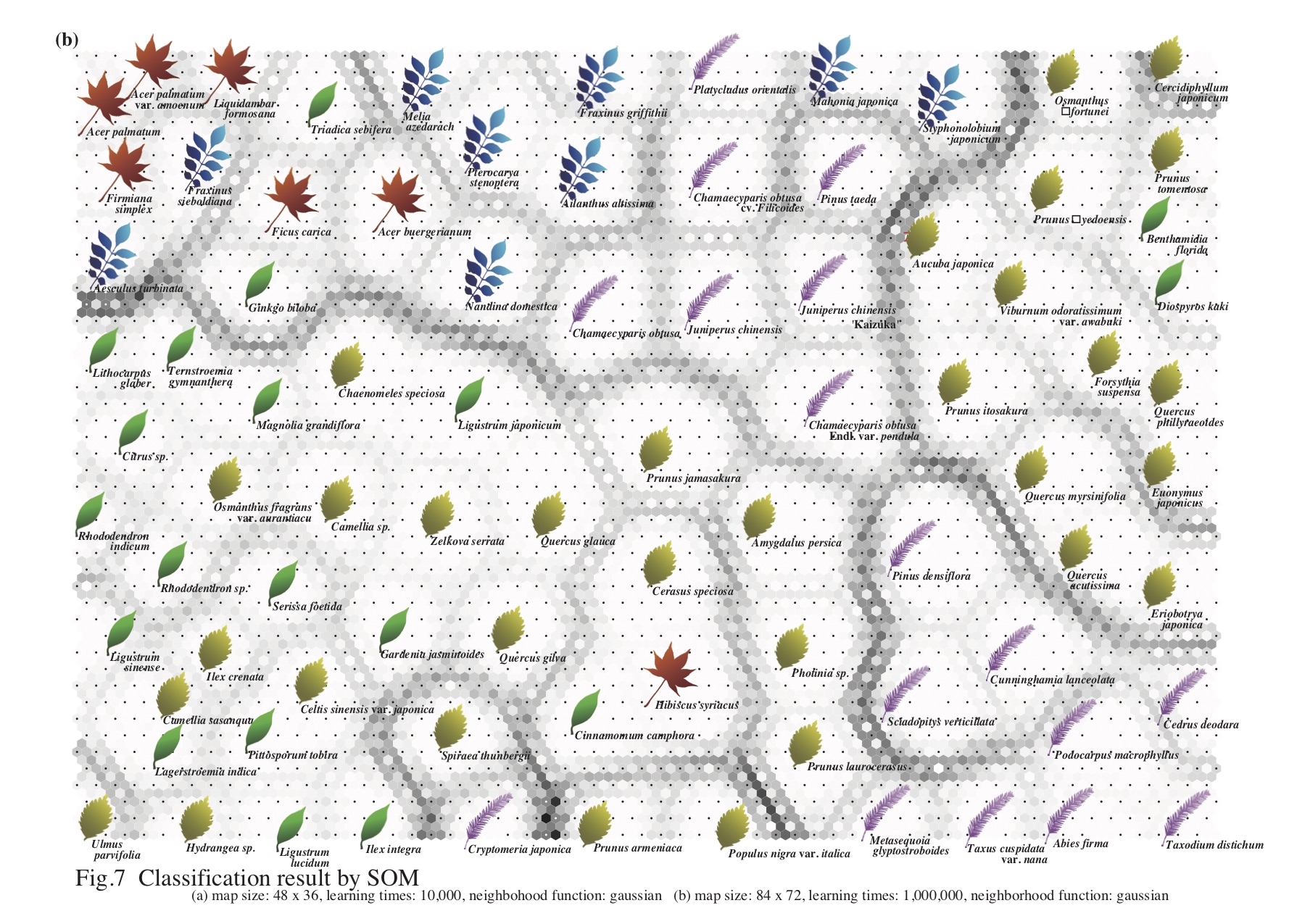
- 1. 自己組織化マップと決定木を用いた画像分類:葉画像から抽出した画像特徴量に対し,自己組織化マップと決定木を用いて画像分類を試みた。入力情報には,葉画像から算出した円形度,短径・長径比,容量次元4次元,情報次元4次元の4因子10次元の画像特徴量を用いた。画像分類では,まず,自己組織化マップを用いて10次元データを2次元平面上へ非線形写像として図示した。そして,5つの決定木アルゴリズムを用いた分類モデルを導出し分類精度を比較・検討した。その結果,形状の違いによって,フラクタル次元は異なる値を示し,予測・分類するための因子として有効であることがわかった。また,十分に学習を行うことにより,すべての樹種を自己組織化マップ上で明瞭に分類することができた。決定木による分類では,訓練事例の分類精度はモデルによるばらつきが大きかったが,集団学習アルゴリズムを適用することにより分類精度が改善されることがわかった。
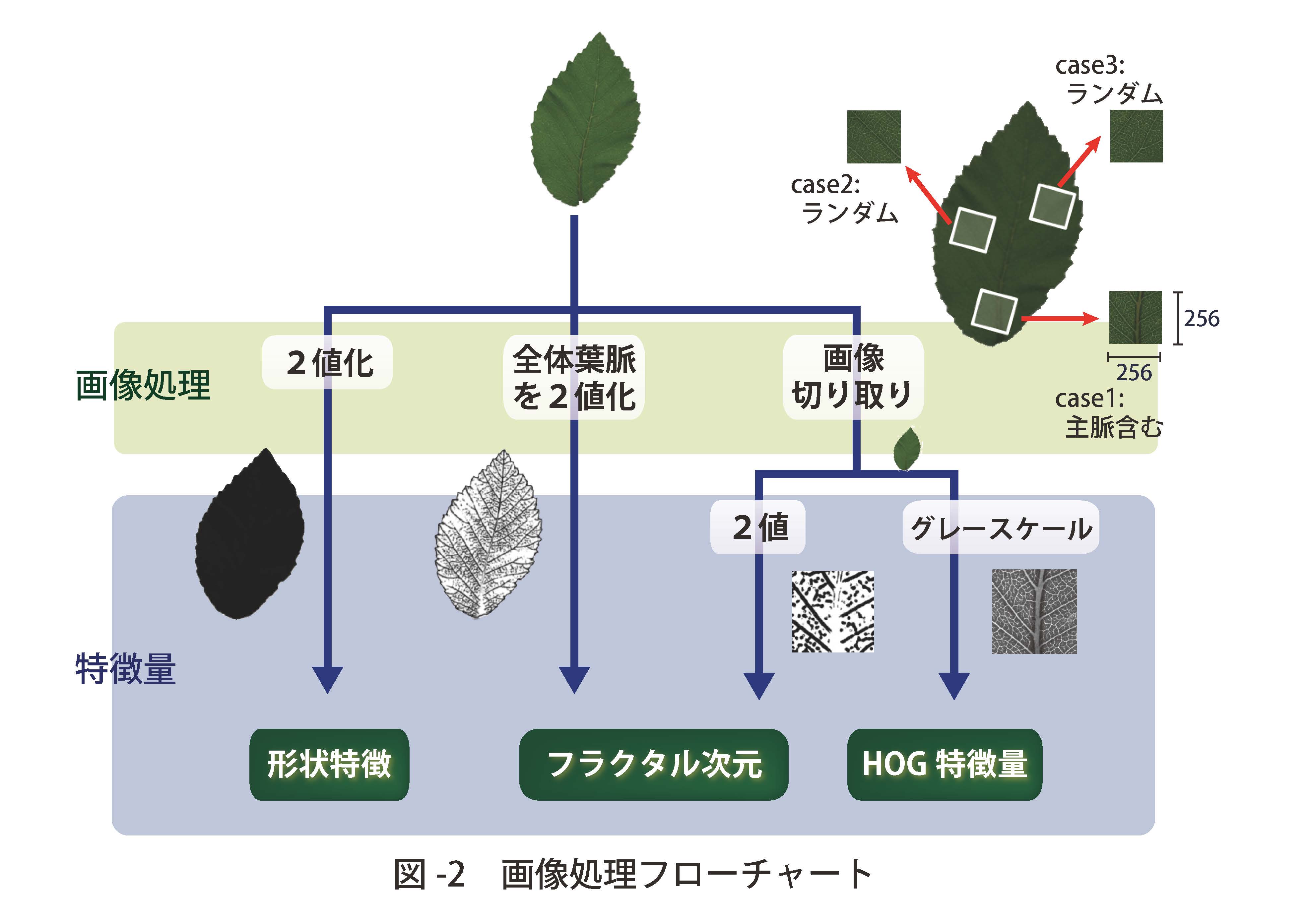
- 2. 葉の形状情報と葉脈情報を用いた分類:
- 3. 野外で撮影した画像を用いた分類:
- 4. 深層学習を用いた分類:

6. 天然林択伐施業における選木技術に関する研究
天然林択伐施業では,収穫木の選定は非常に重要な作業の一つである。収穫木の選定では,収穫した樹木から経済的な収入を得ることに加え,収穫を行った林分において収穫後の林分材積や林分の価値成長が増大するよう配慮する必要がある。また,収穫木を選定する際,樹高や直径といった定量的な情報だけでなく,立木の材質や形質に関する情報,立木配置や他木との競争関係,林内全体を見渡したときに考慮するべき情報,といった様々な情報も必要となるため,誰もが同じように収穫木の選定を行えるわけではない。そこで,収穫木の選定に関わる基準とその指標,特に外観から判定される指標(外観指標)を取り上げ,立木の外観指標や選木者の選木経験が天然林択伐施業の選木意思決定に及ぼす影響について検討した。
1. 立木の外観指標や選木者の選木経験が天然林択伐施業の選木意思決定に及ぼす影響:選木者が収穫調査に関わった経験年数と選木との間に関連性が見られること,収穫木として選定した立木では,腐れなどの材質の欠陥に関わる外観指標が多く見られたこと,選木者は立木の外観指標を見誤るより見落としする傾向が明らかとなった。
2. 決定木を用いた選木規則の抽出:機械学習を用いて選木結果に影響すると思われる重要な属性の機械的な抽出,収穫木の選定およびその選木規則の抽出を試みた。その結果,機械学習を用いると人間が解析すると見落としがちな出現回数が少ない外観指標であっても規則を作る上で重要な属性であれば機械的に抽出することができ,さらに抽出した属性を用いて収穫木を分類することが可能であるといった成果を得ることができた。
 3. ベイジアンネットワークを用いた立木外観指標間の関連性解析:
3. ベイジアンネットワークを用いた立木外観指標間の関連性解析:
 7. 森林内の音場環境(サウンドスケープ)に関する研究
7. 森林内の音場環境(サウンドスケープ)に関する研究